Benchmark Overview: Word Error Rate (WER) & Character Error Rate (CER)
Music AI continuously benchmarks performance of our various AI models to achieve state-of-the-art performance. This study evaluates the transcription performance of Music AI’s Lyric Transcription model compared to OpenAI’s model (Whisper).
The analysis includes the impact of running transcription on mixed audio tracks versus isolated vocal tracks and the benefits of incorporating source separation techniques provided by Music AI.
Key Points
- The advantage of Music AI's approach in handling mixed and isolated vocal tracks and the benefits of integrating source separation techniques to improve transcription accuracy.
- The benchmark uses two objective measurements: Word Error Rate (WER) and Character Error Rate (CER), both of which are widely accepted in research as measures of accuracy.
- The evaluation used an openly available dataset covering multiple languages and music genres, underscoring the benchmark's comprehensive nature.
Importance
WER (Word Error Rate) and CER(Character Error Rate) are objective metrics widely accepted across the research community for consistently measuring transcription accuracy. Lower CER & WER scores indicate higher transcription accuracy.
Definitions
Word Error Rate (WER) measures the number of word errors (substitutions, deletions, insertions) divided by the total number of words in the reference text. WER is a crucial metric for assessing the overall accuracy of transcribed words, directly affecting the usability of the transcriptions in practical applications. Character Error Rate (CER) measures the number of character errors divided by the total number of characters in the reference text. CER is a critical metric for evaluating the precision of each character in the transcription, which is essential for languages with complex spelling and grammar.
Datasets
Music AI's Data Science team performed the evaluation on the open source which consists of 80 royalty-free songs (20 per language) + 20 songs from Portuguese from the same catalogue. The evaluation set consists of multiple genres including rock, pop, reggae, hiphop, folk and jazz. We benchmarked our results against 's text-to-speech API.
Conclusion
When transcription is applied to mixed audio tracks, Music AI’s model exhibits remarkable performance as it was built to be optimized for transcribing lyrics from vocal stems. This approach ensures superior transcription accuracy for vocals, as the model is optimized to handle vocal-specific audio with exceptional precision. The model’s architecture and training regimen are designed to address the unique characteristics of sung vocals, setting it apart from general-purpose transcription models. This distinction underscores the unique advantage of Music AI’s specialized focus on vocal stems, making it ideally suited for transcription tasks involving music.
The targeted fine-tuning of Music AI’s model enables it to accurately transcribe nuanced vocal elements, which general-purpose models like Whisper may overlook or misinterpret.
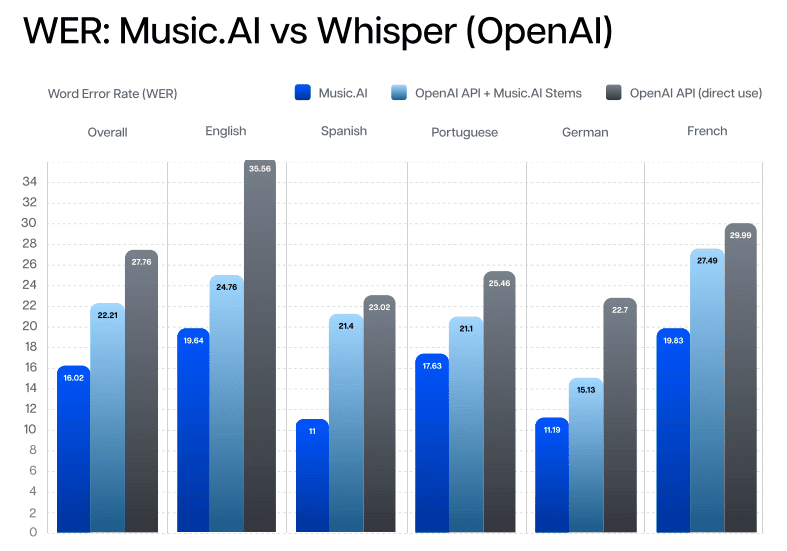
On average, Music AI's transcription results have a Word Error Rate 27.49% lower than OpenAI.
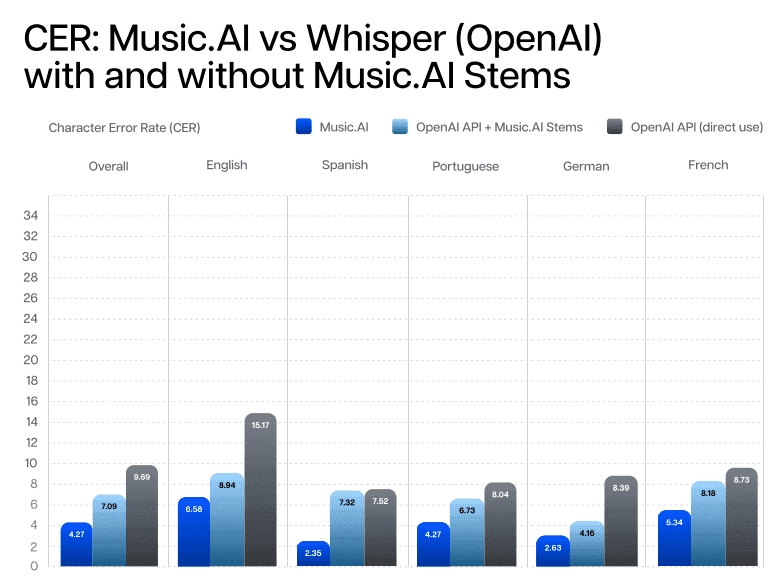
On average, Music AI's transcription results have a Character Error Rate 38% lower than OpenAI.
Technical Insights
Music AI models are meticulously fine-tuned to work synergistically with music source separation techniques. This fine-tuning process enhances the transcription results, especially compared to OpenAI’s models, which are not optimized for this specific task. However, the performance advantage diminishes when transcriptions are run on mixed audio tracks, as Music AI’s model is not fine-tuned for these types of inputs.
The benchmarking process highlights the necessity of incorporating source separation to achieve optimal transcription results.
For those committed to using OpenAI’s transcription services, integrating Music AI’s source separation can significantly boost transcription quality, providing a competitive edge in accuracy and reliability. This process can be independently run by anyone and is expected to yield similar results.
More About Stem Separation
Music AI transcription is fine-tuned to work in conjunction with its own source separation architecture and provides better results than other combinations of disparate transcription and stem separation tools. Other stem separation models tend to generate artifacts that adversely affect transcription quality.
See our Source Separation Benchmark Report for an comparative analysis of commercial and open-source stem separation technology.
