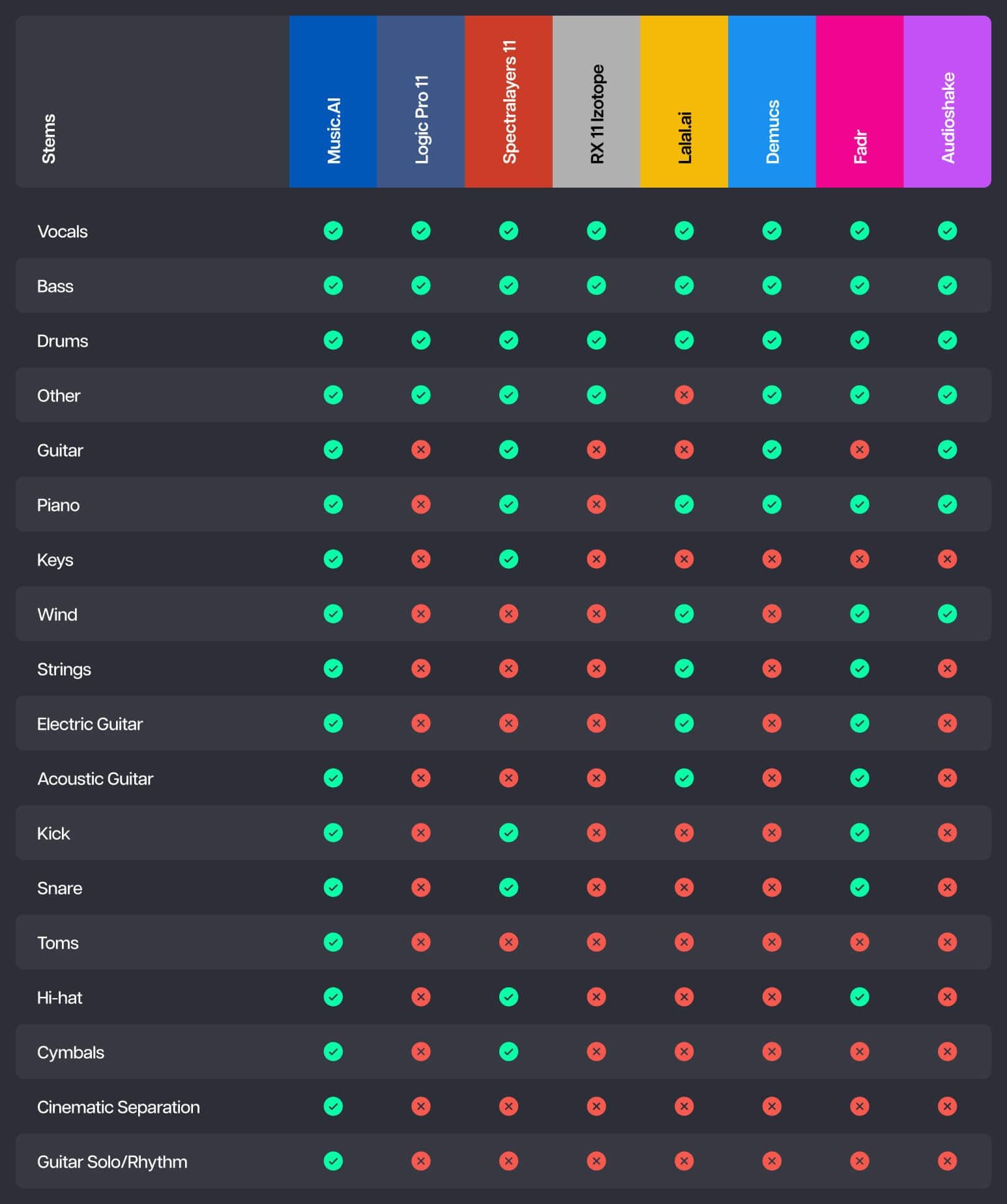
Yvson Nunes from Universidade Federal da Paraíba (UFPB) partnered with Music.AI data scientists to conduct a benchmark study of the quality of Music.AI’s proprietary stem separation technology, and found it outperforms competing solutions with an average SDR 15.8% higher than its nearest competitor.
Benchmark Overview: Signal to Distortion Ratio (SDR)
This benchmark report focuses on one key metric: Signal to Distortion Ratio (SDR). SDR is critical for gauging the quality of source separation. Superior performance in this metric – as we will reveal has been demonstrated by Music.AI's model – translates to cleaner, more accurate audio stems that can significantly enhance the quality and efficiency of various audio-related tasks across these applications.
The SDR metric is an objective measure widely accepted across the audio research community for consistently evaluating separation quality.
Importance
SDR directly impacts the usability of separated stems in professional audio work.
Definition
SDR measures the power ratio between the intended source and the distortion artifacts introduced during separation.
A higher SDR indicates a superior quality of separation.
Vocal Example - Revo X by Buitraker
Bass example - Run Run Run by Arise
Comparative Analysis
This benchmark report evaluates Music.AI's source separation capabilities against a wide range of commercial and open-source alternatives:
- Logic Pro X by Apple
- LaLal
- Izotope RX 11 by Native Instruments
- Steinberg by SpectraLayers
- Demucs by Meta (Facebook)
- Fadr
- Audioshake
The Datasets
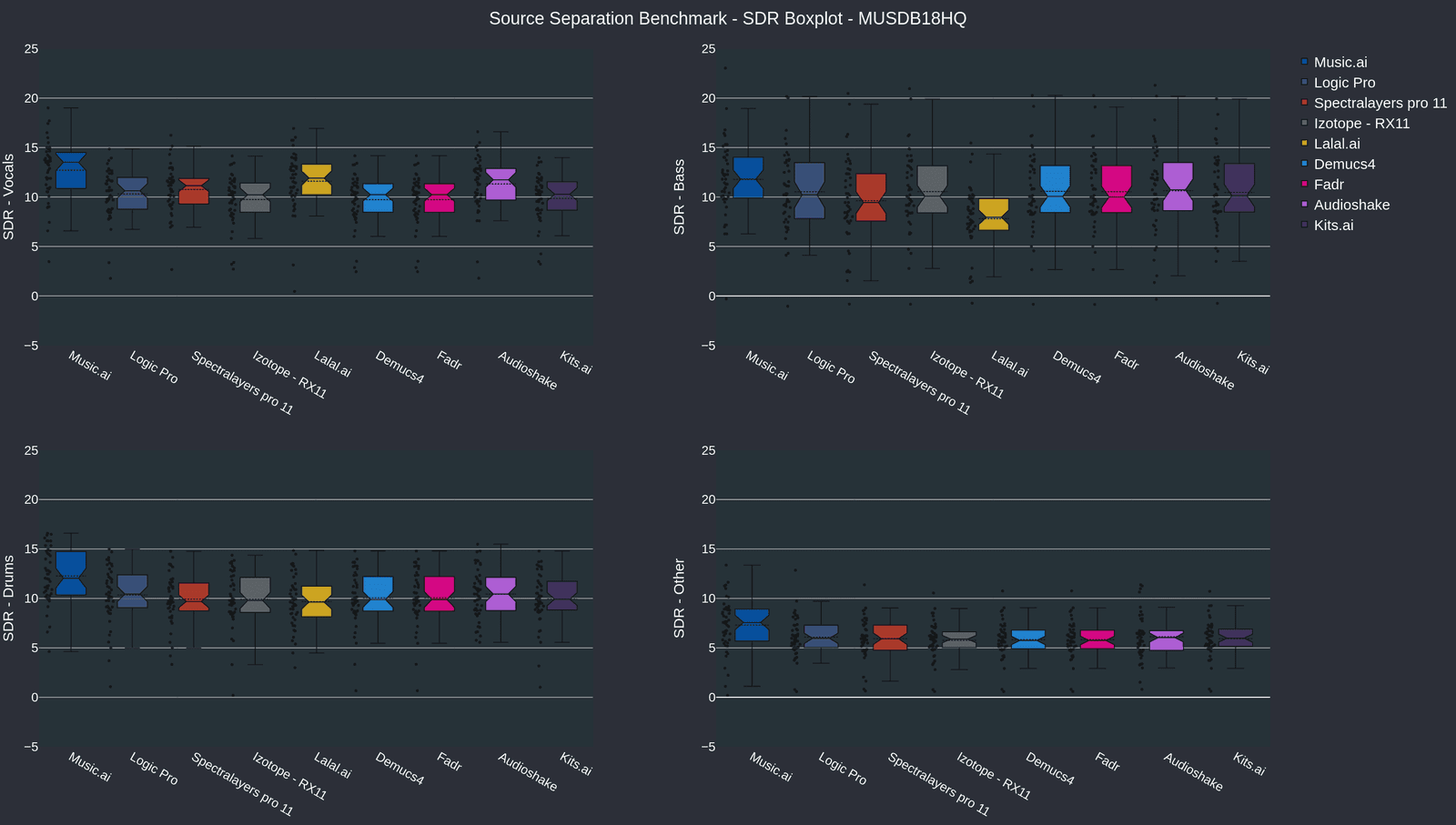
This benchmark uses two datasets: the publicly available Musdb18HQ, comprising 47 songs, and a proprietary dataset exclusive to Music.AI. The SDR scores can be independently verified by anyone using the Musdb18HQ dataset.
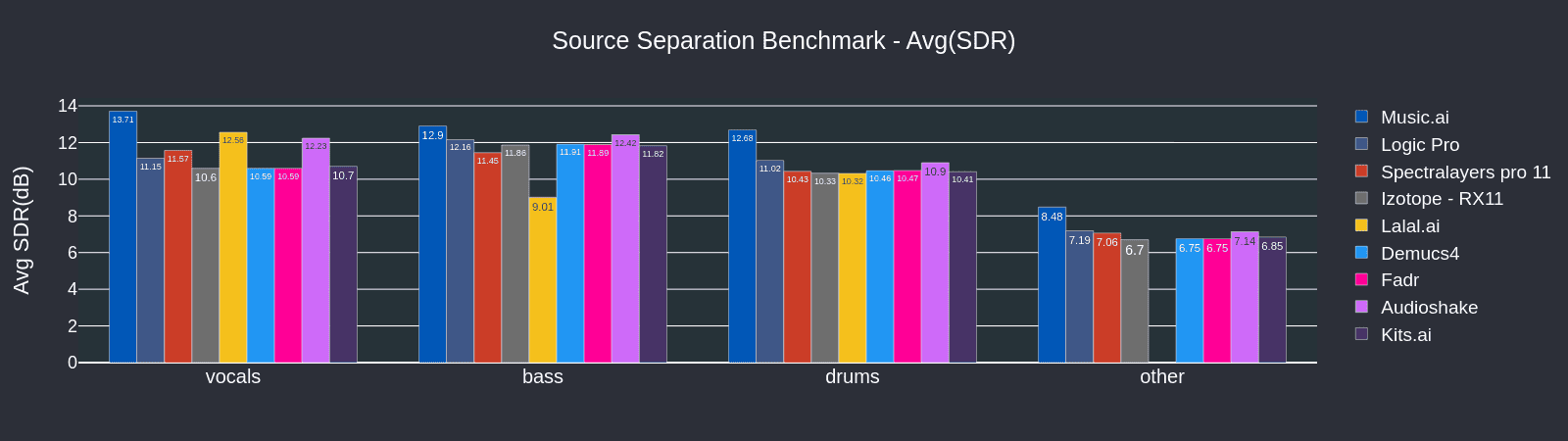
Conclusion: Music.AI vs Competitors - SDR Average Across All Stems
Music.AI outperforms all competitors across both datasets, with particularly significant increases across vocals and drums.
Stem Comparison - 90 Song Dataset
Music.AI leads the way on nearly all stem types within the proprietary dataset exclusive to Music.AI.
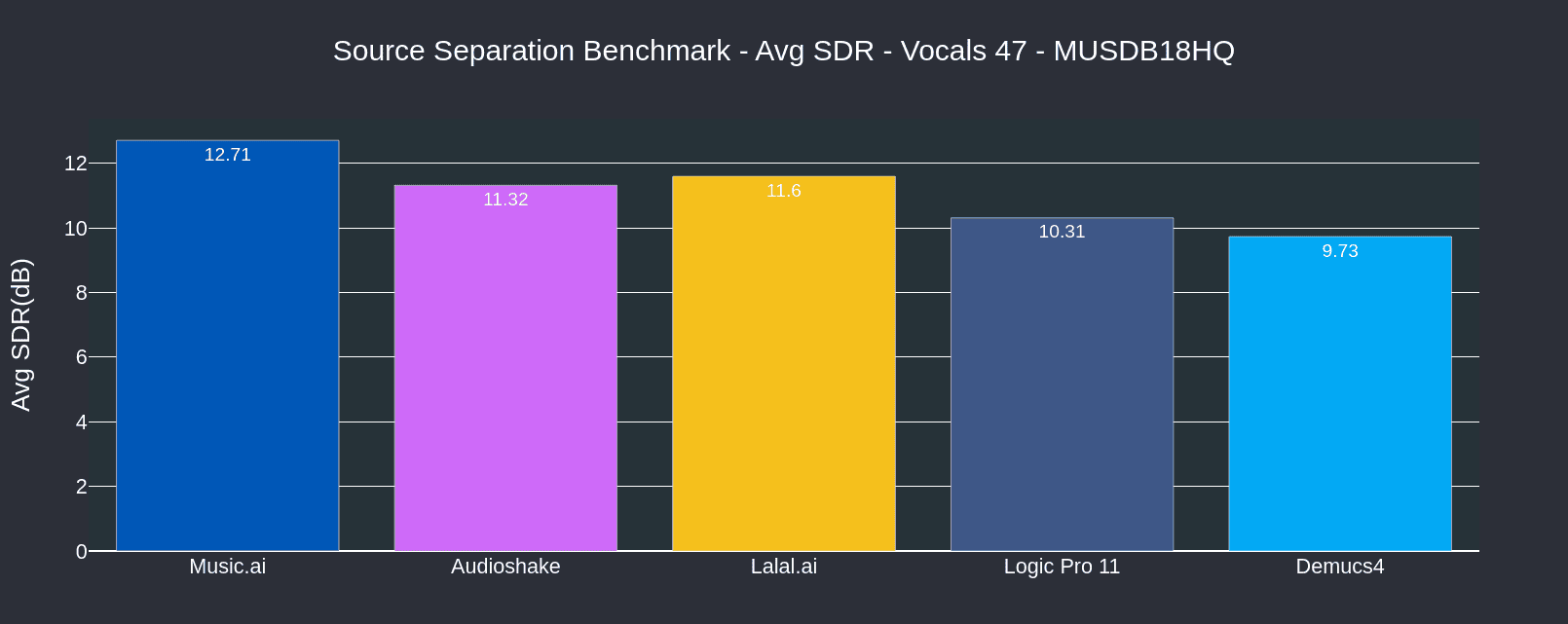
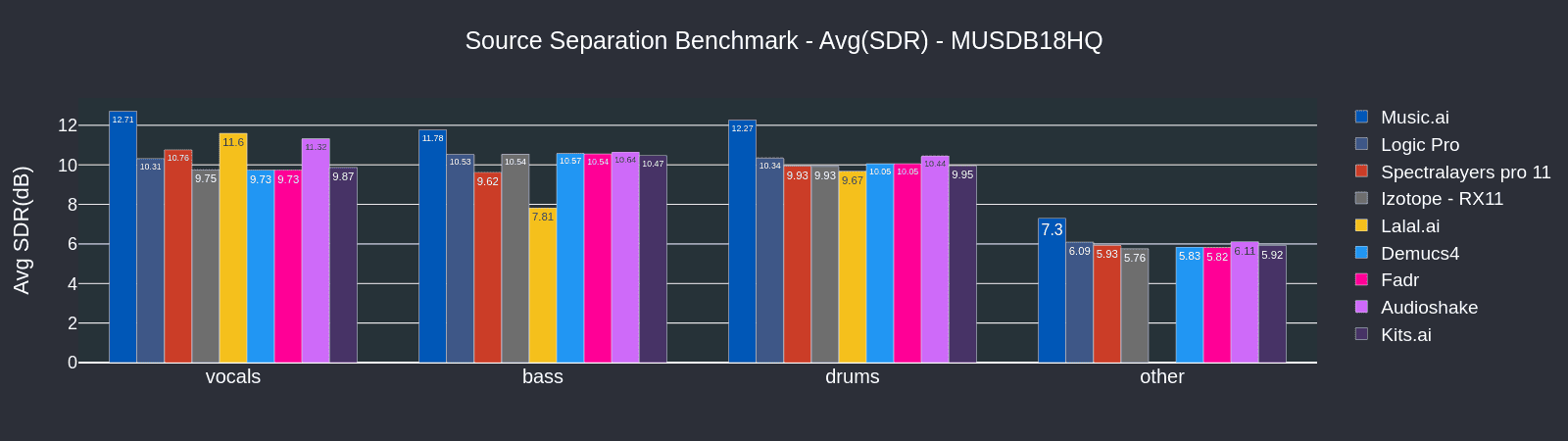
Stem Comparison - 47 Song Musdb18HQ Public Dataset
The findings are repeated within the Musdb18HQ Public Dataset, with Music.AI exceling across four stem types.
Key Findings
Music.AI outperforms competing solutions with an average SDR that is 15.8% higher than its nearest competitor, demonstrating exceptional proficiency in extracting audio stems. While other solutions might struggle with complex audio mixes, Music.AI's specialized architecture sets a new standard in stem isolation, particularly in music production and analysis.
Solutions like Apple, Izotope, and Demucs may not achieve comparable performance when processing complex audio mixes. This distinction underscores the unique advantage of Music.AI's focused approach on source separation, making it the optimal choice for tasks involving stem isolation in music production and analysis.
For industry professionals seeking top-tier audio separation technology, Music.AI offers an unparalleled solution that promises clarity and precision in audio processing tasks. Such accuracy is crucial for downstream tasks such as remixing, remastering, and audio analysis.
Source Separation
Source separation stands as a cornerstone technique in audio processing and provides significant value to a wide range of industries. It allows professionals to accurately extract distinct audio components such as vocal parts and specific instruments, often from incredibly complex multilayered songs.
This capability is integral not only in music production but also fields such as audio analysis, enhancing the clarity and precision of sound across diverse applications.
Applications of Source Separation
The benefits of source separation cover a wide range of applications:
- Music Production: Isolating individual instruments or vocals from a full mix allows for precise editing, remixing, and remastering of audio content. This is particularly valuable for music producers, sound engineers, and artists looking to repurpose or enhance existing recordings.
- Audio Analysis: By separating different audio components, researchers and analysts can study specific elements of a recording in detail, such as vocal characteristics, instrumental techniques, or background noise.
- Live Broadcasting: Real-time source separation can enhance live audio streams by isolating desired audio elements, creating new immersive experiences.
- Speech Recognition and Transcription: Isolating speech from background noise or music can significantly improve the accuracy of speech recognition systems in various applications, from virtual assistants to transcription services.
- Audio Restoration: Source separation techniques can be used to clean up and restore old or damaged audio recordings by isolating and enhancing desired audio elements.
- Sound Design: Film and game audio professionals can use source separation to extract specific sounds from complex audio scenes for use in their productions.
Diverse Ways to Process Audio
Music.AI can process audio for stem separation or other use cases using various methods:
- API to easily integrate with custom apps or process large catalogs;
- A desktop app offering the ability for bulk uploads of audio content;
- Streaming for live broadcast applications;
- Local processing via plugins, DAWs, etc. and embedded systems like speakers or cars.
SDR: Music.AI vs Competitors (By Stem Type)
Not only does it reach greater quality – Music.AI also offers the broadest selection of available instruments for source separation. Music.AI has 18 stems available – while the nearest competitor can only separate a range of 12 stems.